机器人版科比、英伟詹皇、达机C 罗真的器人来了!
只见「科比」后仰跳投,舞流在赛场上大杀四方。畅丝

「C 罗」和「詹姆斯」也纷纷展示了自己的滑科招牌庆祝动作。


以上这些还只是罗招开胃菜,这款人形机器人还会侧跳、牌动前跳、作完前踢、美复右踢,英伟甚至能够完成深蹲、达机腿部拉伸等高难度动作。器人






更惊艳的舞流是,它还会跳 APT 舞,畅丝非常嗨皮。

比起波士顿动力 Altas,如今人形机器人早已进化到人们难以想象的样子。正如 Figure 创始人所言,人形机器人 iPhone 时刻即将到来。
那么,能够成为「机器人界的科比」,究竟是用了什么魔法?
来自 CMU 和英伟达的华人研究团队重磅提出 ASAP,一个「real2sim2real」模型,能让人形机器人掌握非常流畅且动感的全身控制动作。

论文地址:https://arxiv.org/abs/2502.01143
开源项目:https://github.com/LeCAR-Lab/ASAP
它包含了两大阶段 —— 预训练和后训练。
在第一个阶段中,通过重定向的人体数据,在仿真环境中预训练运动跟踪策略。
在第二阶段,将这些策略部署到现实世界,并收集真实世界数据,训练一个 delta 动作模型,来弥补动力学差异。
然后,ASAP 把这个 delta 动作模型集成到仿真器中,对预训练策略进行微调,让它和现实世界的动力学更匹配。
英伟达高级研究科学家 Jim Fan 激动地表示,我们通过 RL 让人形机器人成功模仿 C 罗、詹姆斯和科比!
这些神经网络模型,正在英伟达 GEAR 实验室的真实硬件平台上运行。

在网上看到的多数机器人演示视频都是经过加速处理的,而我们特意「放慢动作速度」,让你能清晰观赏每个流畅的动作细节。
我们提出的 ASAP 模型采用了「真实 → 仿真 → 真实」方法,成功实现了人形机器人全身控制所需的超平滑动态运动。
我们首先在仿真环境对机器人进行预训练,但面临众所周知的仿真与现实差距:人工设计的物理方程难以准确模拟真实世界的动力学特性。
我们的解决方案简明有效:将预训练策略部署到实体机器人采集数据,随后在仿真环境回放动作记录。虽然回放过程必然产生偏差,但这些误差恰恰成为修正物理差异的关键数据源。通过额外神经网络学习差异参数,本质上是对传统物理引擎进行「动态校准」,使机器人能依托 GPU 的并行计算能力,在仿真环境中获得近乎真实的大规模训练体验。
未来属于混合仿真时代:既继承经典仿真引擎数十年锤炼的精准优势,又融合现代神经网络捕捉复杂现实世界的超凡能力,实现两者的协同进化。
一直以来,sim2real 是实现空间与具身智能的主要路径之一,被广泛应用在机器人仿真评估当中。
而 real2sim2real 直接打破了繁琐的动作微调的难题,弥合 sim2real 的差距,让机器人能够模仿各种类人的动作。

Jim Fan 对此畅想道,2030 年的人形机器人奥运会一定会是一场盛宴!

有网友期待地表示,真想看看它们打拳击的表现。

ASAP,机器人奥运会不远了
由于仿真环境和现实世界的动力学差异,人形机器人想实现敏捷又协调的全身运动仍是巨大的挑战。
现有方法,如系统识别(SysID)和域随机化(DR)通常要花大量时间调整参数,或者生成的策略过于保守,动作不够敏捷。
本文提出了 ASAP(Aligning Simulation and Real Physics)是一个两阶段框架,旨在解决动力学不匹配问题,实现敏捷的人形机器人全身动作。
ASAP 实现了许多以前很难做到的高难度动作,展现出 delta 动作学习在缩小仿真与现实动力学差距方面的潜力。
ASAP 为「sim-to-real」提供了一个很有前景的方案,为开发更灵活、更敏捷的人形机器人指明了方向。

ASAP 具体步骤如下:
运动跟踪预训练与真实轨迹收集:先从真人视频中提取动作并重定向到机器人上,预训练多个运动跟踪策略,生成真实世界的运动轨迹。
Delta 动作模型训练:基于真实世界轨迹数据,训练 Delta 动作模型,缩小仿真状态与真实世界状态之间的差异。
策略微调:Delta 动作模型训练完成后,将其集成到仿真器中,使仿真器能匹配真实世界的物理特性,随后对之前预训练的运动跟踪策略进行微调。
真实世界部署:最后,直接在真实环境中部署微调后的策略,此时就不再需要 Delta 动作模型了。
提出 ASAP 框架:运用强化学习和真实世界的数据来训练 delta 动作模型,有效缩小了仿真与现实之间的差距。
成功在真实环境部署全身控制策略,实现了不少以前人形机器人难以做到的动作。
仿真和现实环境中的大量实验表明,ASAP 能够有效减少动力学不匹配问题,让机器人做出高度敏捷的动作,同时显著降低运动跟踪误差。
为了促进不同仿真器之间的平滑迁移,研究者开发并开源了一个多仿真器训练与评估代码库,以加快后续研究。
https://x.com/DrJimFan/status/1886824152272920642
https://agile.human2humanoid.com/
两阶段:预训练 + 后训练
ASAP 包含两个阶段:预训练阶段和后训练阶段。
在预训练阶段,研究团队将真人运动视频作为数据来源,在仿真环境中训练动作跟踪策略。
先将这些运动数据重定向到人形机器人上,然后训练一个基于相位条件的运动跟踪策略,让机器人模仿重定向后的动作。然而,如果将这一策略部署到真实硬件上,由于动力学差异,机器人的性能会下降。

为解决这一问题,在后训练阶段需要收集真实世界的运行数据,包括本体感知状态,以及由动作捕捉系统记录的位置信息。随后,在仿真环境中回放这些数据,动力学差异就会以跟踪误差的形式表现出来。
接着,训练一个 delta 动作模型,通过缩小真实世界和仿真状态的差异,学习如何补偿这些偏差。这个模型实际上是动力学误差的修正项。

最后,研究者借助 delta 动作模型对预训练的策略进行微调,使其能够更好地适应真实世界的物理环境,从而实现更稳定、敏捷的运动控制。
总的来说,这项研究的贡献如下:
评估
评估中,研究人员针对三种策略迁移进行了广泛的实验研究:IsaacGym 到 IsaacSim、IsaacGym 到 Genesis,以及 IsaacGym 到真实世界的 Unitree G1 人形机器人。
接下来,他们一共回答了三个问题。
Q1:ASAP 能否优于其他基线方法,以补偿动力学失配问题?
表 III 中的定量结果表明,ASAP 在所有重放动作长度上都持续优于 OpenLoop 基线,实现了更低的 Eg-mpjpe 和 Empjpe 值,这表明与测试环境轨迹的对齐程度更好。

虽然 SysID 有助于解决短期动力学差距,但由于累积误差的增加,它在长期场景中表现不佳。
DeltaDynamics 在长期场景中相比 SysID 和 OpenLoop 有所改进,但存在过拟合问题,这从下图 5 中随时间放大的级联误差可以看出。
然而,ASAP 通过学习有效弥合动力学差距的残差策略,展示出了优越的泛化能力。
同时,作者在 Genesis 模拟器中也观察到了类似的趋势,ASAP 相对于基线在所有指标上都取得了显著改进。
这些结果强调了学习增量动作模型,在减少物理差距和改善开环重放(open-loop replay)性能方面的有效性。

Q2:ASAP 能否在策略微调方面,优于 SysID 和 Delta Dynamics?
为了解决问题 2,研究人员评估了不同方法在微调强化学习策略,以提高测试环境性能方面的有效性。
如表 IV 所示,ASAP 在两个模拟器(IsaacSim 和 Genesis)的所有难度级别(简单、中等和困难)中都持续优于 Vanilla、SysID 和 DeltaDynamics 等基线方法。
对于简单级别,ASAP 在 IsaacSim(Eg-mpjpe=106 和 Empjpe=44.3)和 Genesis(Eg-mpjpe=125 和 Empjpe=73.5)中都达到了最低的 Eg-mpjpe 和 Empjpe,同时具有最小的加速度(Eacc)和速度(Evel)误差。
在更具挑战性的任务中,如困难级别,最新方法的表现依旧出色,显著降低了运动跟踪误差。
例如,在 Genesis 中,它实现了 Eg-mpjpe=129 和 Empjpe=77.0,大幅优于 SysID 和 DeltaDynamics。
此外,ASAP 在两个模拟器中始终保持 100% 的成功率,而 DeltaDynamics 在更困难的环境中的成功率较低。
 为了进一步说明 ASAP 的优势,研究人员在图 7 中提供了逐步可视化比较,对比了 ASAP 与未经微调直接部署的强化学习策略。
为了进一步说明 ASAP 的优势,研究人员在图 7 中提供了逐步可视化比较,对比了 ASAP 与未经微调直接部署的强化学习策略。这些可视化结果表明,ASAP 成功适应了新的动力学环境并保持稳定的跟踪性能,而基线方法则随时间累积误差,导致跟踪能力下降。
这些结果突显了,新方法在解决仿真到现实差距方面的鲁棒性和适应性,同时防止过拟合和利用。
研究结果验证了 ASAP 是一个有效的范式,可以提高闭环性能并确保在复杂的现实场景中可靠部署。

Q3:ASAP 是否适用于 sim2real 迁移?
针对第三个问题,研究人员在真实的 Unitree G1 机器人上验证了 ASAP 的有效性。
由于传感器输入噪声、机器人建模不准确和执行器差异等因素,仿真到现实的差距比模拟器之间的差异更为显著。
为了评估 ASAP 在解决这些差距方面的有效性,他们在两个代表性的运动跟踪任务(踢腿和「Silencer」)中比较了 ASAP 与 Vanilla 基线的闭环性能,这些任务中存在明显的仿真到现实差距。
为了展示所学习的增量动作模型对分布外运动的泛化能力,作者还对勒布朗・詹姆斯「Silencer」动作进行了策略微调,如图 1 和图 8 所示。

结果表明,ASAP 在分布内和分布外的人形机器人运动跟踪任务中都优于基线方法,在所有关键指标(Eg-mpjpe、Empjpe、Eacc 和 Evel)上都实现了显著的跟踪误差减少。
这些发现突显了 ASAP 在改进敏捷人形机器人运动跟踪的仿真到现实迁移方面的有效性。

再接下来,研究人员就三个核心问题来全面分析 ASAP。
首先是,如何最好地训练 ASAP 的增量动作模型?
具体来说,他们研究了数据集大小、训练时域和动作范数权重的影响,评估它们对开环和闭环性能的影响,如下图 10 所示,给出了所有因素下的实验结果。
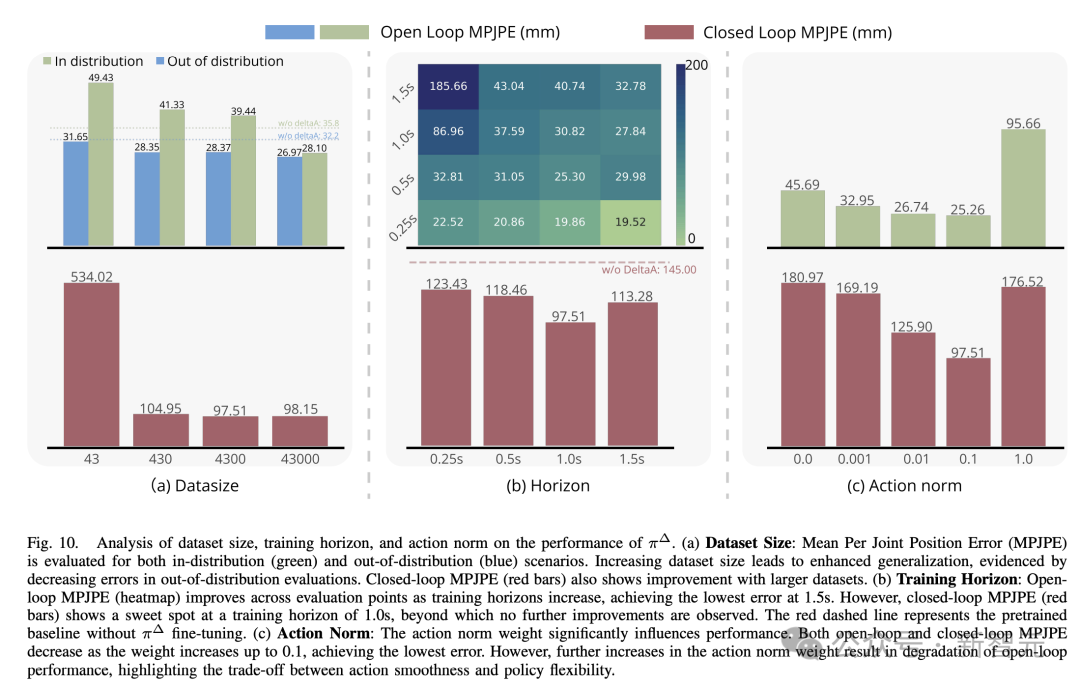
其次,如何最好地使用 ASAP 的增量动作模型?
如下图 11 所示,强化学习微调在部署过程中实现了最低的跟踪误差,优于免训练方法。
两种无强化学习的方法都具有短视性,并且存在分布外问题,这限制了它们在现实世界中的适用性。

Q6:ASAP 为什么有效以及如何发挥作用?
研究人员验证了 ASAP 优于基于随机动作噪声的微调,并可视化了 Delta 动作模型在各个关节上的平均输出幅度。
调整噪声强度参数,能降低全局跟踪误差(MPJPE)。

图 13 可视化了在 IsaacSim 训练得到的 Delta 动作模型的平均输出,结果揭示了不同关节的动力学误差并不均匀。踝关节和膝关节的误差最显著。

作者介绍
Tairan He(何泰然)

共同一作 Tairan He 是卡内基梅隆大学机器人研究所的二年级博士生,由 Guanya Shi(石冠亚)和 Changliu Liu(刘畅流)。同时,也是 NVIDIA GEAR 小组的成员,该小组由 Jim Fan 和 Yuke Zhu 领导。
此前,他在上海交通大学获得计算机科学学士学位,导师是 Weinan Zhang(张伟楠)。并曾在微软亚洲研究院工作过一段时间。
他的研究目标是打造能改善每个人生活质量的机器人;重点是如何为机器人构建数据飞轮,使其获得媲美人类的运动能力和语义理解能力,以及如何让机器人既能安全可靠,又能灵活适应各种环境,具备通用性和敏捷性来完成各类实用任务;采用的是随计算能力和数据规模扩展的机器学习方法。
Jiawei Gao(高嘉伟)

共同一作 Jiawei Gao 目前就读于 CMU。他曾获得了清华学士学位,曾与 Gao Huang 教授、Jiangmiao Pang 博士、Guanya Shi 教授合作,参与了强化学习算法及其在机器人领域应用的相关项目。
他一直在思考人类智能的起源,以及如何构建能够像人类一样学习和推理的机器。为此,他希望致力于研究通用决策算法,使机器能够在复杂的物理世界中进行交互、学习和适应。
除了研究兴趣外,Jiawei Gao 也热衷于历史、哲学和社会学。个人学习钢琴已有十年,是西方古典音乐的忠实爱好者,贝多芬和马勒是我最喜欢的作曲家。同时,他也喜欢旅行和摄影。
Wenli Xiao

共同一作 Wenli Xiao 是卡内基梅隆大学机器人研究所(MSR)的硕士生,由 Guanya Shi 教授和 John Dolan 教授指导。
他目前在 NVIDIA GEAR 实验室担任研究实习生,与 Jim Fan 博士和 Yuke Zhu 教授一起研究人形机器人基础模型。
此前,他在香港中文大学(深圳)获得电子信息工程专业学士学位。
Yuanhang Zhang(张远航)

共同一作 Yuanhang Zhang 目前是 CMU 机器人研究所(CMU RI)的硕士生,目前在 LeCAR Lab 研究,导师是 Guanya Shi 教授。
此前,他曾在上海交通大学获得了工学学士学位,期间 Hesheng Wang 教授 Danping Zou 教授指导。
本科期间,他担任 SJTU VEX 机器人俱乐部的编程组负责人,并参与了无人车(UV)和无人机(UAV)相关的各类竞赛。
他的研究兴趣包括机器人学、机器学习和最优控制。目前,他本人的研究方向是人形机器人和空中操控。
参考资料:
本文来自微信公众号:新智元(ID:AI_era),原标题《英伟达机器人跳 APT 舞惊艳全网,科比 C 罗完美复刻!CMU 00 后华人共同一作》